JupyterHub#
Jupyter notebooks and the Jupyter ecosystem#
You may have heard of Jupyter – an open computing “ecosystem” developed by Project Jupyter. This ecosystem is described succinctly and effectively in the online open book, Teaching and Learning with Jupyter:
Project Jupyter is three things: a collection of standards, a community, and a set of software tools. Jupyter Notebook, one part of Jupyter, is software that creates a Jupyter notebook. A Jupyter notebook is a document that supports mixing executable code, equations, visualizations, and narrative text. Specifically, Jupyter notebooks allow the user to bring together data, code, and prose, to tell an interactive, computational story. (“2.2 But first, what is Jupyter Notebook?”)
We will use the JupyterLab software to create, manage and run Jupyter notebooks. You will be exposed to Jupyter notebooks throughout the hackweek, including in most tutorials. To learn more about Jupyter, Jupyter notebooks and JupyterLab:
Check out several sections in the Teaching and Learning with Jupyter online open book, specially Chapter 5 Jupyter Notebook ecosystem.
See the OceanHackWeek 2020 pre-hackweek tutorial “Jupyter and Scientific Python basics: numpy, pandas, matplotlib”, which demonstrates effective Jupyter use both on your computer (“locally”) and on JupyterHub: Jupyter notebooks — tutorial video. The video includes Q&As at the end where you’ll find common questions you may find asking yourself.
See the resources at the end of this page.
How do I access the shared cloud environment?#
Access to our shared cloud environment by clicking on https://nmfs-openscapes.2i2c.cloud

You can now click on the “Log in to continue” button, then on the next screen click on “Sign in with GitHub” to grant JupyterHub the required permissions. In the next window, enter your GitHub username (or email address) and password.
Next, you will need to select the environment (server) you want to launch: Python or R
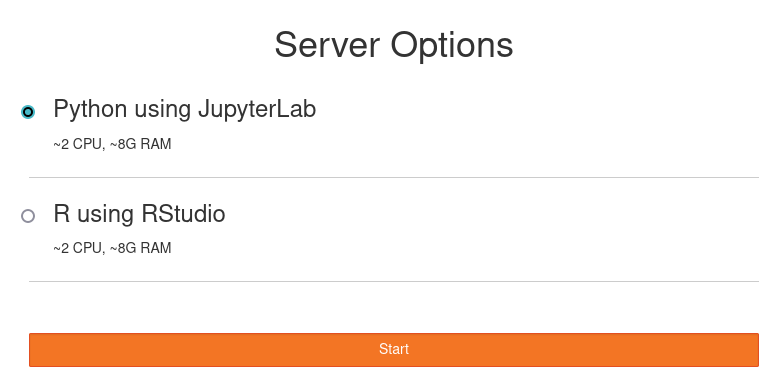
After making your selection, you will see something like this while the JupyterHub server environment is loading:
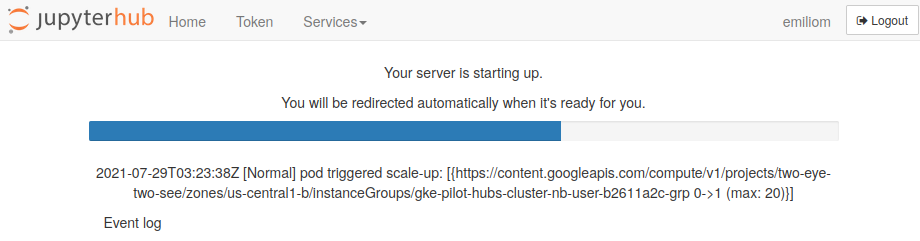
It will take a bit of time for this to load - be patient! Once things are spun up, if you selected Python you will see your very own cloud instance of a JupyterLab graphical user interface:
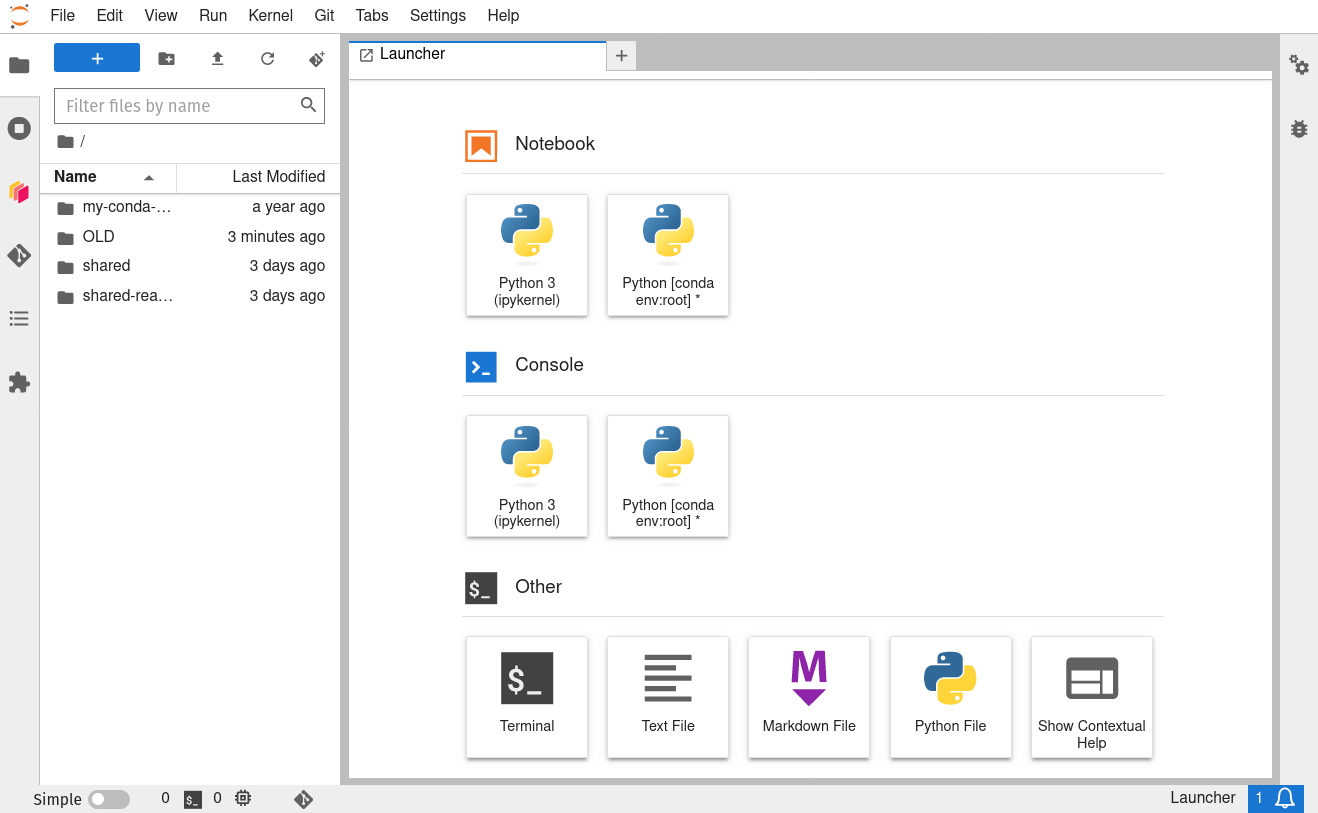
If you selected R, you will see your very own cloud instance of RStudio:
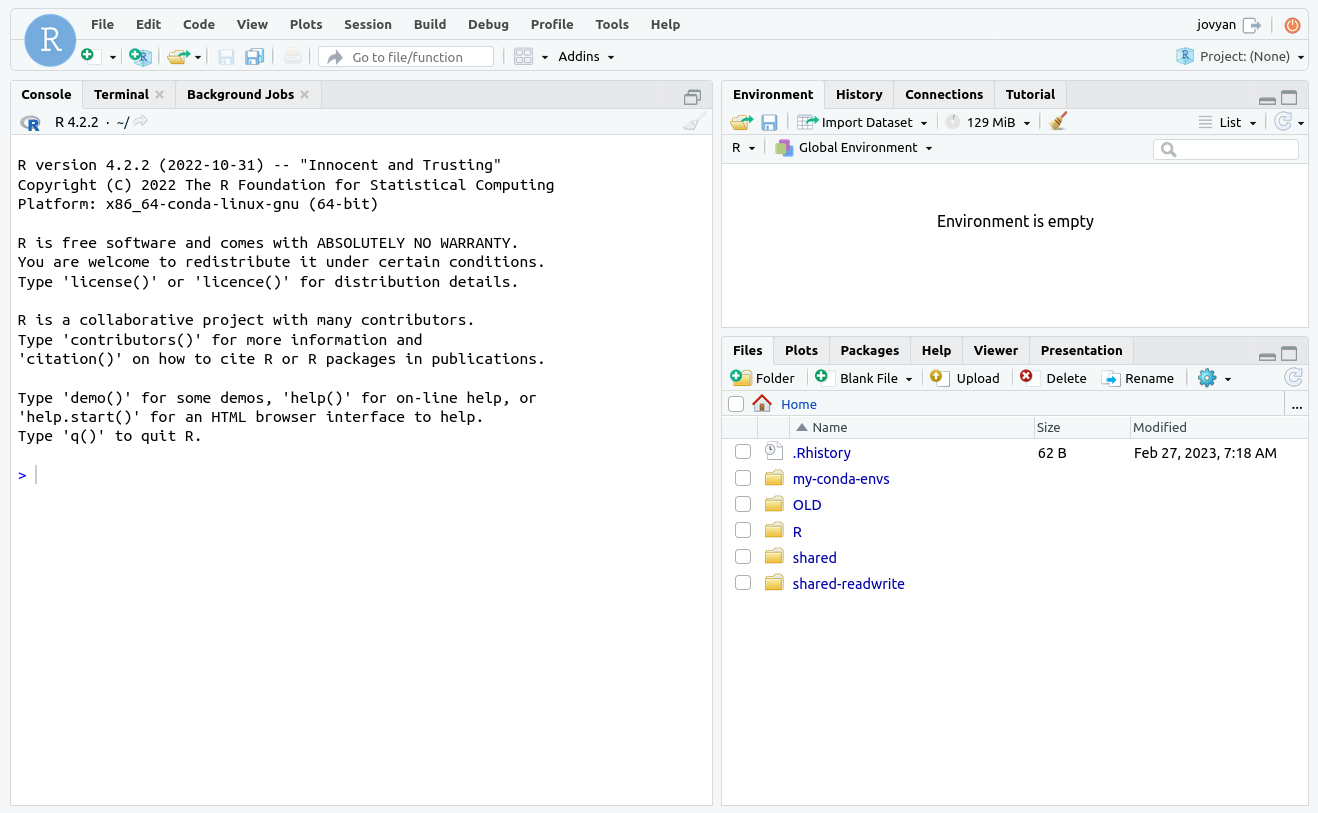
How do I get the tutorial repository?#
For the tutorials, there are two primary ways of getting the notebooks. You can use the traditional git management route (described below), or you can use the magical nbgitpuller link below.
Pull tutorial repo via the magic of nbgitpuller
The nbgitpuller link is magical, but it can’t detect which profile you are currently running. Either should update the (same) tutorial repo, but it may error if you use the Python link if you are actively using the R profile, or the other way around.
Nbgitpuller is nice, because it will automatically merge any changes you make with the changes from the upstream repo on subsequent pulls (i.e., when you click the links above again) via a series of sane rules.
You can accomplish the same results as nbgitpuller when using git directly, but it can take a complicated dance of git add, git stash, git pull, and git stash apply to keep your changes and get the changes from upstream.
Warning
If you start by using the nbgitpuller link and then switch to using git directly, or if you already have a copy of the repository in your account from a previous OHW, using the nbgitpuller link again will most likely lead to unpredictable results.
This can be fixed by removing, renaming, or moving the ohw-tutorials directory and using nbgitpuller again.
{kind=link}
How do I get my code in and out of JupyterHub?#
When you start your own instance of JupyterHub you will have access to your own virtual drive space. No other JupyterHub users will be able to see or access your data files. Next we will explain how you can upload files to your virtual drive space and how to save files from JupyterHub back to another location, such as GitHub or your own local laptop drive.
First we’ll show you how to pull some files from GitHub into your virtual drive space. This will be a common task during the hackweek: at the start of most tutorials we’ll ask you to “clone” (make a copy of) the GitHub repository corresponding to the specific tutorial being taught into your JupyterHub drive space.
To do this, we will need to interface with the JupyterHub file system. JupyterHub is deployed in a Linux operating system and we will need to open a terminal within the JupyterHub JupyterLab interface to manage our files. There are two ways to do this: (1) Navigate to the “File” menu, choose “New” and then “Terminal” or (2) click on the “terminal” button in JupyterLab:
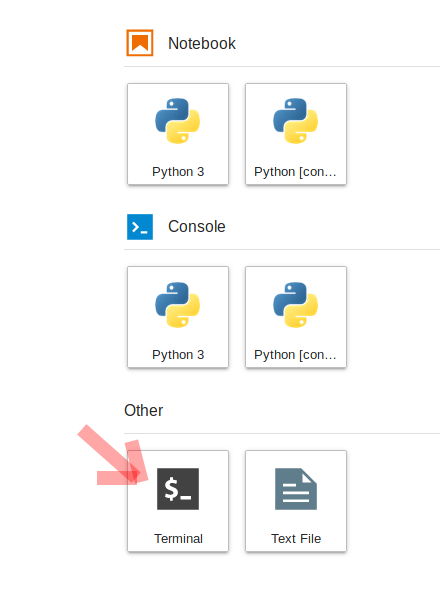
This will open a new terminal tab in your JupyterLab interface:
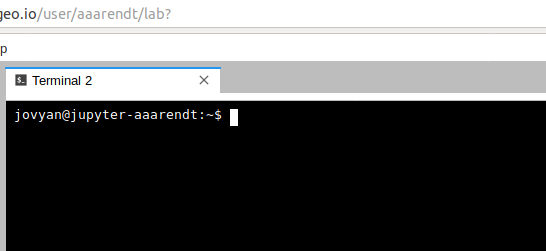
You can issue any Linux commands to manage your local file system.
Now let’s clone a repository (see the Git Setup and Basics page). We’ll illustrate this with the ohw-tutorials repository. First, navigate in a browser on your own computer to the repository link oceanhackweek/ohw-tutorials. Next, click on the green “Code” button and then copy the url into your clipboard by clicking the copy button (clipboard icon):
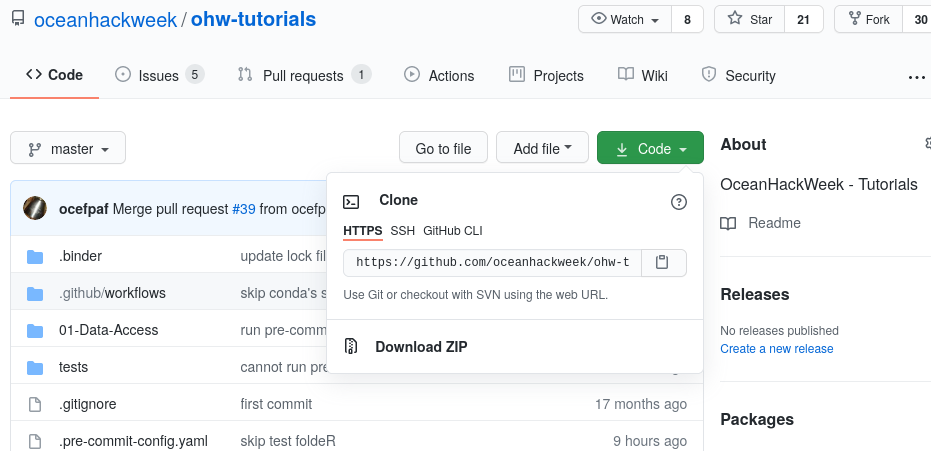
Now navigate back to your command line in JupyterLab. Type git clone and then paste in the url:
git clone https://github.com/oceanhackweek/ohw-tutorials.git
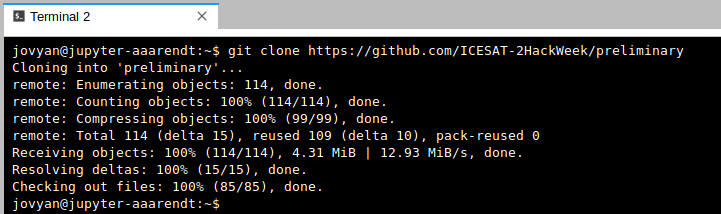
After issuing the git clone command you should see something like this (again, the screenshot below is for a different repo, but the concept is identical):
End your Hub session every day. Will I lose all of my work?#
When you are finished working for the day or for an extended period of time, it is important to explicitly shutdown your JupyterHub session, to reduce the load on our cloud infrastructure and overall costs.
To shutdown your server:
If you are using JupyterLab, you access the control via File > Hub Control Panel menu item:
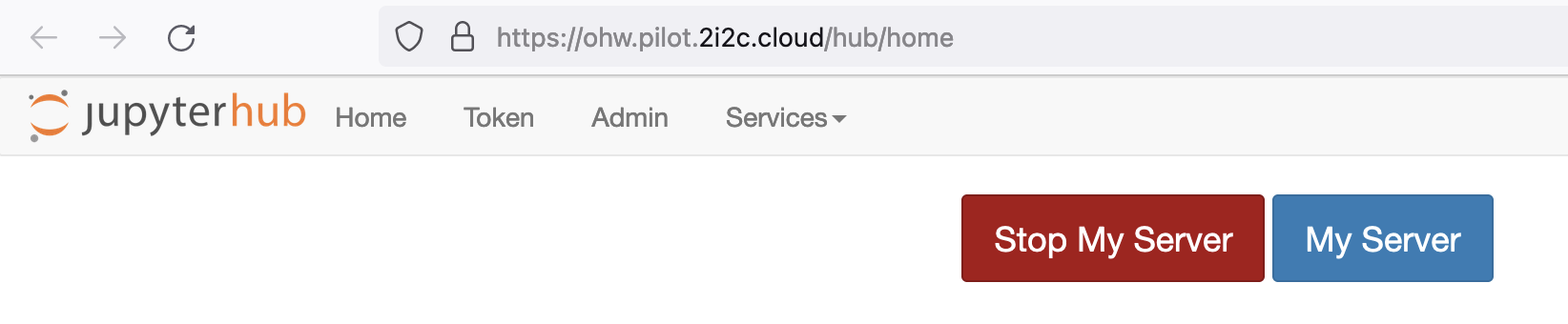
Then you can shut down your server from your hub control panel (which you can also access directly from https://workshop.nmfs-openscapes.2i2c.cloud/hub/home):
Note that the menu item File > Log Out doesn’t actually shut down the server, so please follow these steps instead.
If you are using RStudio, the Log out and Quit session entries under the File menu won’t do much! Shut down your server from your hub control panel https://workshop.nmfs-openscapes.2i2c.cloud/hub/home), as described above.
Note
You will not lose your work when shutting down the server. Shutting down (Stop My Server) will NOT
cause any of your work to be lost or deleted. It simply shuts down some resources.
It would be equivalent to turning off your desktop computer at the end of the day.
How do I do distributed computation?#
Dask is available on the JupyterHub for distributed compute.
To start up a Dask cluster, call
from dask.distributed import Client
from dask_gateway import GatewayCluster
cluster = GatewayCluster()
client = Client(cluster)
# xarray becomes even more awesome
And then either call cluster on it’s own line in a cell and use the UI, or cluster.scale(NUMBER_OF_WORKERS_TO_SCALE_TO).
Note
Just as it can take a few minutes for JupyterHub to start up your server, it can also take a few minutes before Dask workers become available.
We are working on making Dask (and server) scaling faster, but no promises of faster scaling at this point.
Similar to your server, please shutdown your Dask clusters when you are done.
cluster.shutdown() # or cluster.close()
References and Resources#
Teaching and Learning with Jupyter, an online open book.
OceanHackWeek 2020 pre-hackweek tutorial “Jupyter and Scientific Python basics: numpy, pandas, matplotlib”: Jupyter notebooks — tutorial video.
From https://dataquest.io